För någon vecka sedan hade jag en lektion med femmorna om Internet och Google. Det var den första av tre inplanerade lektioner som är en del av att de ska skriva i Wikimini, om ALMA-pristagare. Min roll är att jobba lite med informationssökning och källkritik, klassens lärare leder läsning och litteratursamtal samt låter eleverna skriva faktatexter om författare.
Så här gick lektionen till:
Eleverna fick prata två och två om vad Internet är. När vi lyfte i helklass blev svaren av typen vad som finns på Internet, alltså Youtube, spel etcetera.
Därefter tittade vi på de första 4.24 minuterna av Internet – så funkar det! där Internet beskrivs mer tekniskt som ett nätverk. Jag tog mig inte tid till att diskutera filmsnutten eftersom det kändes viktigare den här gången att prata om Google.
På Active Boarden öppnade jag sedan google.se och frågade eleverna vad Google skulle göra om jag skrev ordet Tensta. Svaret blev att Google plockar fram fakta om Tensta.
Det här är viktigt tycker jag: att eleverna förstår att Google är en sökmotor, ett program, en maskin, som letar efter ordet – inte en människa som förstår att vi står här i skolan i Hjulsta och vill hitta fakta. Så det försökte jag förklara. Jag berättade också att man kan tänka att en Google-spindel springer runt i nätverket, men inte överallt, och samlar in en massa uppgifter i en databas. Den är oftare på ställen som uppdateras ofta, och mer sällan på ställen där det inte händer så mycket. Och när vi gör en sökning i Google så sker den i databasen.
Sedan googlade vi på ”Tensta” och tittade på vad vi såg på skärmen. Jag tycker också att det är viktigt att eleverna reflekterar över vad de ser, inte bara klickar på översta träffen. Medan jag fortsatte att använda termerna sökmotor, program och maskin så tittade vi på hur många träffar det var, kollade var faktarutan till höger hämtat sin information ifrån (Wikipedia, vilket det ofta är) samt pratade om att Google ofta plockar fram bra information till oss.
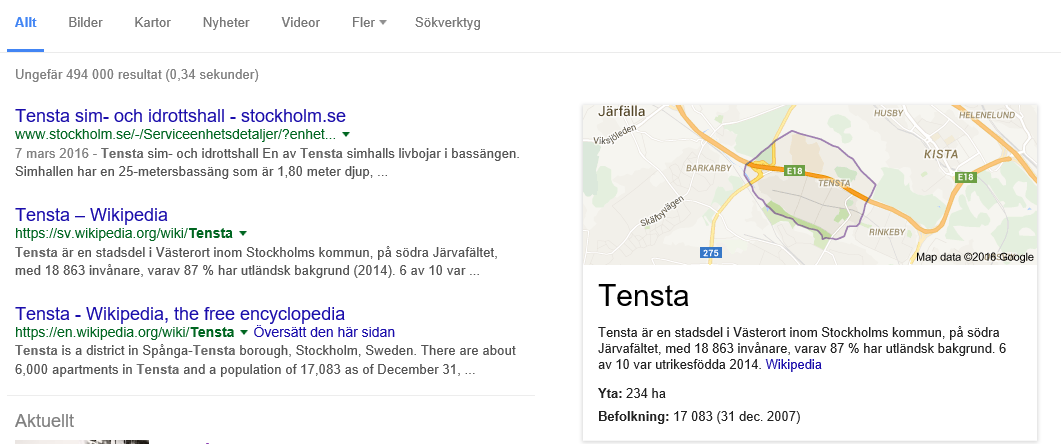
Varför är då de översta träffarna ofta bra? Jag vet ju inte riktigt själv, men vi pratade i alla fall om att det handlar om algoritmer, alltså beräkningar som är inprogrammerade i Google. Till de faktorer som påverkar sorteringen hör: om ordet finns i webbadressen, om det finns i rubriker och om det förekommer många gånger, om det finns många länkar till en webbsida och kanske även många länkar från. Eleverna föreslog att det också kan handla om att många klickar på just den länken, och det låter väl troligt.
Jag visade även vad som händer om man söker på ordet ”mattor”, då kommer nämligen flera annonser överst.
Eleverna fick sedan arbeta två och två vid en dator. Jag hade gjort ett papper de skulle fylla i, efter att ha gjort en enkel sökning på termer jag gett dem. Termerna valde jag ut för att det kunde vara intressant att jämföra resultat från de olika paren, men vi hann ganska lite av det. Varje par fick en av följande termer: Karl XII, Karl III, frisyr, frisör, Stockholm, Ryssland, Estelle, Victoria, sjörövare, pirater.
Eleverna skulle anteckna:
1. Hur många träffar har ni fått?
2. Finns det någon informationsruta till höger?
3. Varifrån är informationen hämtad i så fall?
4. Finns det annonser eller aktuellt överst i träfflistan?
5. Titta på de tre översta träffarna (efter eventuella annonser och aktuella träffar). Varför tror ni att de har kommit överst?
Eleverna jobbade på fint, vi vuxna gick runt och hjälpte till och jag tyckte att eleverna reflekterade och funderade klokt.
Till det vi hann lyfta efteråt hörde skillnaden i antalet träffar på ”Stockholm” och ”Ryssland”. Varför var det många fler träffar när man sökte på ”Stockholm”? Eleverna spekulerade, men när vi började diskutera vad ”Stockholm” respektive ”Ryssland” heter på olika språk så tror jag vi var närmast sanningen.
Cilla Dalén, Hjulsta grundskola


Senaste kommentarer